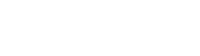In this article, we explore why testing on the negative side of software is so important. Confirmatory (positive) testing only tests to ensure that software works as it should. It doesn’t seek to find where software is not working as expected. However, testing to “break” software requires a different mind-set. This article will explain how to gain that mindset by applying proven and creative testing techniques.
Introduction
One of the most common complaints I hear from test managers is that their teams tend to stay on the “happy path” of using and testing applications. Instead of testing software to find where it doesn’t work correctly, these testers have the objective of testing software to “make sure it works correctly.”
At first, testing to prove that software works as it should sounds good. However, this positive or confirmatory testing is a weak test because it is easy to show in a variety of scenarios how a particular software application or system can work correctly without ever encountering a failure.
One of my sayings is that “In testing, failure is not an option – it’s an objective.”
A key attribute of a good tester is that of being able to break software for a positive purpose, which is to find the failures before the users find them.

Table Of Contents
- My Negative Testing Story
- Coming to Terms
- The Classic “Triangle Problem”
- What to Do Once You Have “Broken” the Software
- Basic Principles in Negative Testing
- Nine Ways to Design and Perform Negative Tests
- Conclusion
My Negative Testing Story
I come to testing from a development background, with over ten years of coding in highly critical application areas. In those early days of my career, it was uncommon for companies to have a separate test team, so the testing was totally up to the developer.
I will never forget one occasion when I was implementing a change request. I had modified the code and tested it with my own test data to prove it worked. Then, I asked my business user to take it for a spin. He sat at the keyboard and pressed the Enter key with no data in the fields and the whole application crashed!
I was shocked. I asked my client why he tried such a thing and his only response was a shrug and the answer, “I don’t know.”
We both had a good laugh, but that was certainly a lesson learned for me! From that point on, I started to learn how to break my own code and it was a good practice which did wonders for my career as a developer and eventually became the focus of my career as a professional software tester.
Coming to Terms
Before we go any further, let’s look at some definitions. One thing that is very interesting to me is that these are largely non-standard terms. But, these terms are used in some certification programs and have found their way into many testers’ vocabulary.
Positive testing – Testing that is mainly confirmatory in nature. It is a proof of correctness which is a weaker form of testing.
Negative testing - “Testing a component or system in a way for which it was not intended to be used.” (ISTQB Glossary)
If you take a survey of early testing books such as The Art of Software Testing by Glenford Myers, or Software Testing Techniques by Boris Beizer, you will not find these terms mentioned. That is because the working assumption is that testing should be negative in nature to be effective!
The Classic “Triangle Problem”
In The Art of Software Testing, Myers describes a software application for drawing a triangle. There are three fields for entering numbers. If all three values are equal, an equilateral triangle is drawn. If all three are different, a scalene triangle is drawn, and if two values are equal and the third is different, then an isosceles triangle is drawn.
The tester is asked to list as many test conditions as possible.
I use this problem when interviewing testers for jobs and as part of assessments. It is a helpful way to see how creative a tester might be. I have noticed that testers tend to fall into three groups:
Happy path testers – These people will have about three or four test cases and are primarily thinking about what it will take to draw each triangle.
A little tougher – These people will have about ten or so tests and will get off the positive path a little bit.
The devious – These people will have twenty or thirty test cases that will have kinds of valid and invalid input.
How would you do on the triangle problem?
What to Do Once You Have “Broken” the Software
When software fails in the test, we know what needs to be fixed, or do we? If only it were that easy!
The number one question that often arises is, “How likely is it that a typical user would do this?
This is a difficult question to answer because it may be difficult to know who is a “typical” user and how these “typical” users use the software.
It is helpful to remember that users of software do not set out to break the software. The users need the software to work correctly. Software failures are a frustrating experience when trying to complete a task.
More often than not, software failures occur when a combination of conditions or actions take place. It is often likely that a user will stumble across those conditions that are seemingly normal to them, but trigger a failure in the software.
Basic Principles in Negative Testing
-
Not every observed failure is due to a defect.
Some failures may be due to environmental conditions (physical or technical), or to user error. Some failures are due to errors in setting up or performing the test.
-
Ad-hoc testing can break software, but often falls short of being a rigorous test.
“Ad-hoc” in this context is testing that is done at the spur of the moment with little or no forethought and no repeatability because the steps and inputs are not recorded. The tester tries to throw various conditions at the software, but often with no idea how it should perform or what the results should be. The objective is often to get the software to crash or behave in some very odd way.
Not coincidentally, this is a classic hacker technique because if a malicious attacker can get the software to behave in an unpredictable way, they can sometimes exploit that behavior to gain access to the application or system.
-
Good negative tests take some creativity and knowledge of what constitutes correct results.
This is why test design techniques are helpful. These techniques help provide a way to think of negative tests. But, the techniques can take many years to perfect and there are many nuances to applying them.
Nine Ways to Design and Perform Negative Tests
This is a list of proven techniques to design effective tests. If you study the root causes of many of the most deadly and costly software failures, they could have been prevented by testing with these techniques. While some of these techniques work best as specification-based, they can all be applied without defined specifications.
This is not intended to be a complete treatment of the techniques, but rather, a concise overview of each technique with a few examples. In conclusion, I present my recommendations for further study.
-
Equivalence Partitioning
Equivalence partitioning (EP) is a powerful way to identify valid and invalid conditions, as well as reducing the total number of tests needed. Negative tests will fall into the invalid class. But, there is more to the story!
The great purpose and value of EP is that you are able to classify input or outputs of equivalent behavior in distinct partitions or classes. The idea is that instead of testing as many conditions as possible, you can just sample with one or a few conditions in each class. This is where the test case reduction is seen.
The classes are mutually exclusive, but they can be subdivided. You may find in a given situation there are multiple invalid conditions, each with a different cause and effect.
For example, consider a login test. The user name can be invalid because it is missing, or perhaps it is not a user name on record. The invalid input could be too long (such as exceeding an eight-character maximum), or it could be too short (such as a five-character minimum). Perhaps the input is formatted incorrectly (if the user name must be a valid e-mail address), and so forth.
Some EP tests can be applied as ranges of values (Figure 1), while others may be applied as enumerated values (Figure 2).
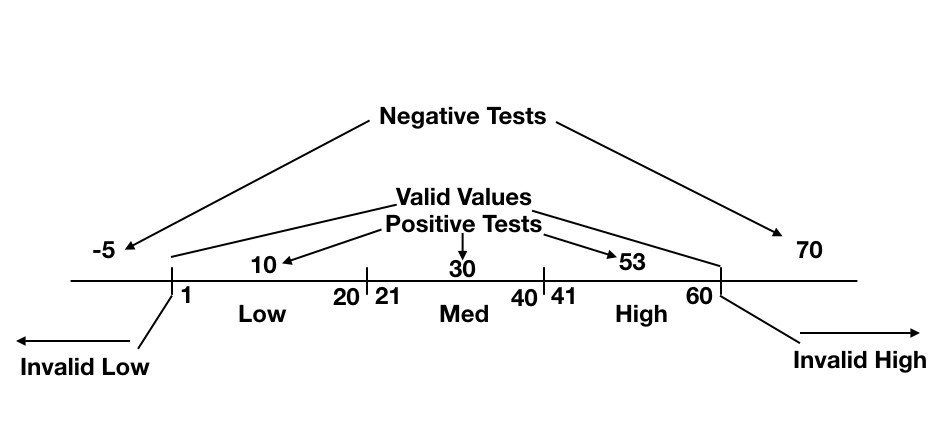
Figure 1 – EP with Ranges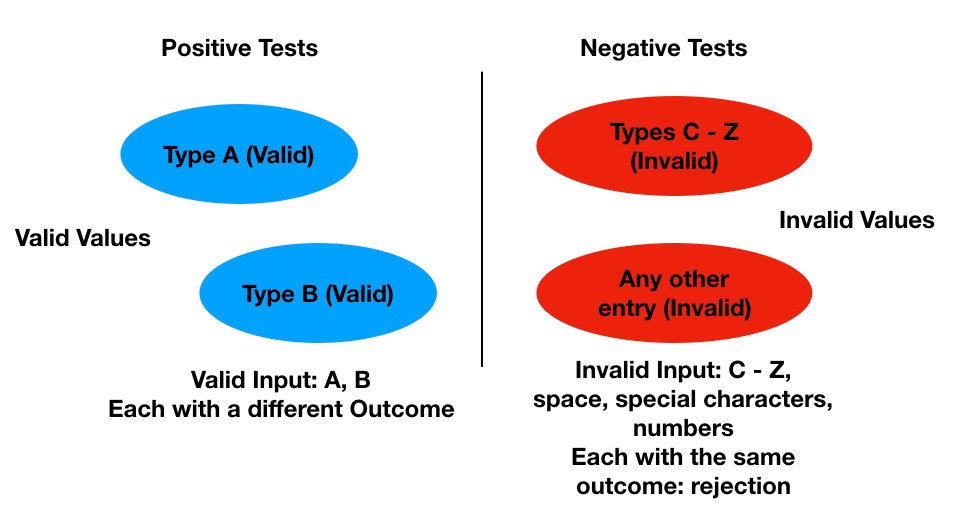
Figure 2 - EP with Enumerated ValuesIn Figure 1, let’s say that we have three ranges for a value: low (values from 1 through 20), medium (values from 21 through 40) and high (values from 41 through 60). Values below 1 are invalid, as are values greater than 60. In addition, only numeric integer values are allowed.
The thing to note in this example shown in Figure 1 is that to meet the criteria of an EP test, choosing any value in the low, medium or high ranges would suffice as a positive test. Any value less than 1 or higher than 60 would be a negative test. Negative tests could also include values that are non-numeric, non-integer, special characters, spaces, null, etc.
In Figure 2, we have various type codes. Choosing any item with a type “A” or “B” code would meet the criteria of testing those classes, respectively, as positive tests. Any other types should be rejected as invalid and would be considered a negative test. Also, like in the previous examples, invalid formatted type code such as numeric types, special characters, spaces, null values, etc., would also be considered negative test conditions.
-
Boundary Value Analysis
Perhaps the most widely used way to identify negative tests is boundary value analysis (BVA). However, I always start with EP, because the partitions often reveal the boundaries. In the situation where there are multiple EPs, there may be two to three times that number of boundary tests. As you consider what happens when you go from one partition to the another, you may go from just below the partition boundary, right on the boundary, and then just above the boundary.
There is a nuance in BVA where some testers prefer the 2-value rule, while others prefer the 3-value rule. I fall into the second camp.
In some cases, this technique may be used when there is a single boundary, such as an amount, a date, time, etc. (Figure 3). In other cases, BVA can be applied when there is a series of ranges, each with a minimum and maximum value (Figure 4).
Figure 3 – BVA with Single Threshold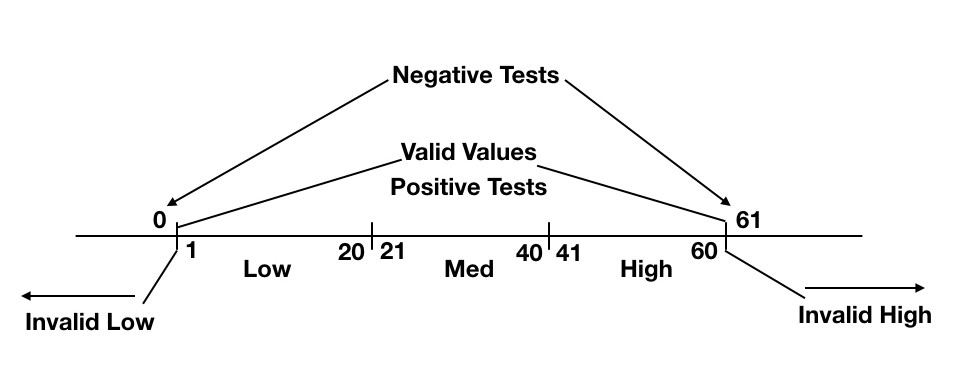
Figure 4 – BVA with RangesIn Figure 3, let’s say we have a business rule that states if someone is 30 days past due on their account, we send them a past-due notice. In this example, on day 29, no notice would be sent. On day 30, a notice would be sent, and on day 31, no notice would be sent because one was sent on day 30. So, positive tests would be on days 29, 30 and 31.
An interesting negative test might be to test a scenario where day 30 happened to fall on a non-processing date, such as a weekend or holiday. Then, what would happen? On which day would the notices actually be sent?
In this scenario, they should be sent on the next available processing date, even though this condition is not explicitly stated in the business rule. Good practice would be to clarify the business rule and test accordingly.
In Figure 4, we see the same situation as in Figure 1, which had the three ranges. However, with BVA, our tests are all based on what happens when we go from one range to the next. The negative tests will be when we cross over to the invalid low range and the invalid high range.
One important thing to remember about BVA is that is typically finds one kind of defect. That is, the use of an incorrect logical operator. For example instead of coding x>10, a developer may code the rule as x>= 10.
-
Error Guessing
Error guessing is another common technique that can be applied based on your own experience as well as the experiences of others. The goal is to identify the triggering conditions for an error message to be displayed, or for a failure to occur. Ideally, you want the error to be caught and displayed in such a way so that the user can correct the situation without a system failure or crash. In the worse case scenario, the error condition is not caught, there is no obvious failure, thereby allowing an incorrect result that causes a more severe “downstream” failure. Sometimes these failures are subtle but impactful.
For example, consider a situation where an incorrect input is accepted in a system for disability payments due to a data input edit not being applied correctly. Perhaps the maximum number of payments might be two hundred and forty months (twenty years of payments). But, the user is allowed to enter a value of twenty-four hundred months. Therefore, the person would get virtually endless payments (two hundred years)! The payments made in excess of twenty years might go undetected for many years and might be unrecoverable. In addition, it might apply to many individuals with a potential catastrophic financial impact for the paying organization.
-
Checklists
Checklists and error guessing go hand in hand as checklists are a great way to document error conditions to test. A sample error guessing checklist is found here (hyperlink to word doc).
Unfortunately, people tend to overlook or minimize the value of checklists because they are too easy to define. They are so basic that people go right past them in the quest for more complex solutions. In reality, checklists can provide value many times over what is costs to create them.
Like many things, execution is critical. Having a checklist is one thing. Using that checklist is another thing altogether.
A great resource on the need for checklists is The Checklist Manifesto by Atul Gawande. A great book for software testing checklists testing is William E. Perry’s book, Effective Methods for Software Testing, Fourth Edition.
-
Exploratory Testing
Exploratory testing, when performed as intended, is not random or chaotic. The idea behind exploratory testing is to learn about the software under test while you are testing it. Then, other tests can be performed based on what you are learning.
Negative testing is a primary form of exploratory testing, as it is common to try many things to see what fails and what succeeds. Sometimes, the failures are things that should have been allowed but were not. Other times, the failures are things that should have been dis-allowed, but weren’t.
Exploratory testing is typically not designed in advance, mainly due to the lack of understanding of the item(s) to be tested. However, test charters can be defined to plan a test session that occurs in a given amount of time, such as one to two hours. This is known as session-based testing.
Exploratory tests can be used as a primary test method, or to supplement other methods. A good practice in exploratory testing is to produce a test report which describes what was tested, what was seen and what was learned. Also, it is good to use the tests performed as a basis for documented tests for future tests, such as regression tests.
A challenge with exploratory testing is being able to manage and report what is done and seen. Session-based testing is a great solution. In session-based testing, tests are performed based on a charter which defines the main objective and scope. PractiTest offers a great feature to perform and document exploratory tests, along with tracking defects and the time spent in the test. Also, documentation such as screenshots can be attached.
Exploratory tests can be included as a test instance in a test set which may also include pre-defined tests (Figure 5).
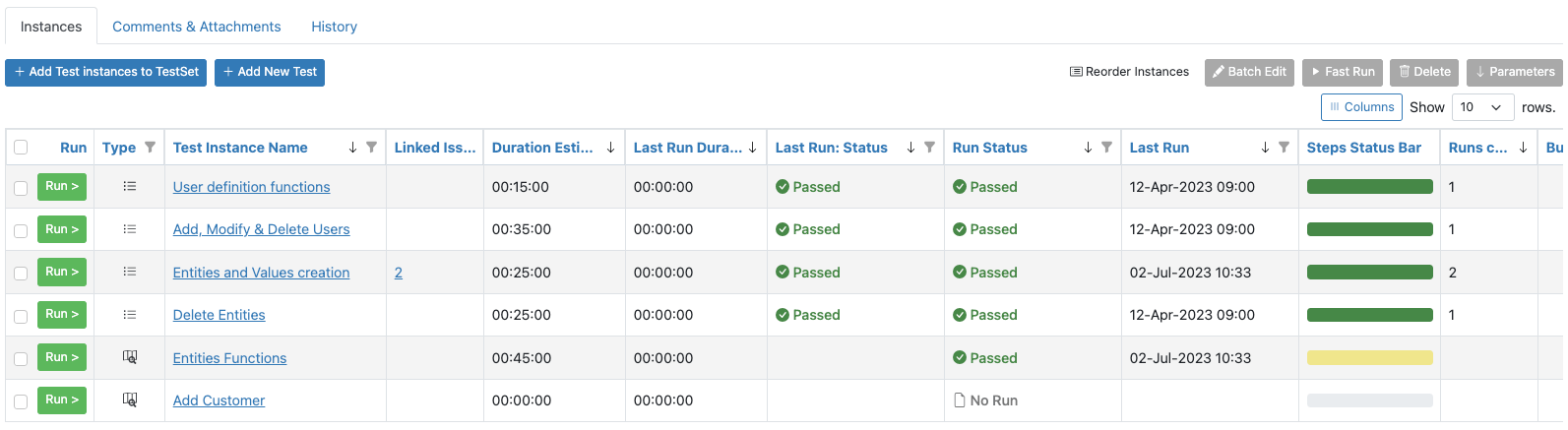
Figure 5 – Exploratory Tests in a Test SetAs the tests are performed, all the details of the test can be documented as they are seen by the tester (Figure 6).
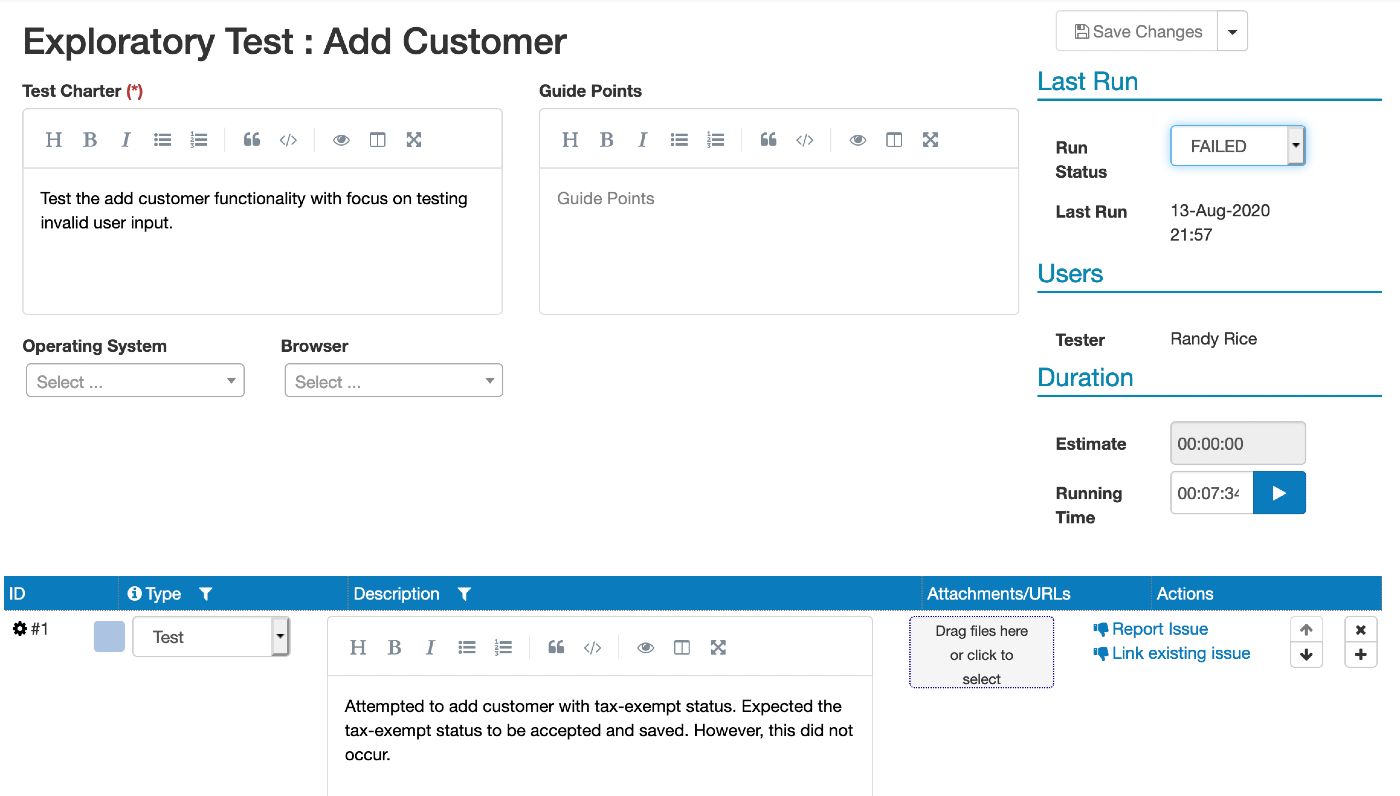
Figure 6 – Exploratory Test Description -
Anti-patterns
Anti-patterns are the opposite of design patterns. A design pattern is a common effective way of solving a problem, whereas an anti-pattern is an ineffective solution. An anti-pattern is not just another way of doing something, it is a bad way to do something. This is what makes an anti-pattern a good source of negative tests – especially those which are process-based.
In many cases, the anti-pattern should not be allowed in the normal use of an application. For example, an application may allow a user to attach an image to a document. The expectation is that the image will be 1 MB or less in size. However, an anti-pattern might be to attach a huge image 50 MB in size. This would be a good negative test.
-
Fuzz Testing
Fuzz testing is the input of random inputs intended to cause crashes, failures or some unexpected behavior. Since the inputs are so random, there are no expected results as in typical negative test cases, just the observation of what might happen. This is a favorite technique of hackers, both ethical and malicious. The goal is to get the software or system to behave in unexpected ways. This opens an opportunity for the hacker to gain access in ways that would normally be prohibited.
Besides unauthorized access, failures can be seen in a variety of ways such as system crashes, odd user interface displays, etc.
A key capability in fuzz testing is to know which input(s) led to the unexpected outcomes. For this reason, a log of inputs is needed. Sometimes this log is recorded or automatically captured in some way.
Another common practice in fuzz testing is automation. Since it normally takes an extended period of fuzz testing to see an unexpected event, automation is the only practical way to sustain this kind of test entry.
-
Small Scale Test Automation
Small scale test automation is an interesting concept somewhat related to fuzz testing, but not as random. The idea is to do the same action perhaps thousands of times to see the impact. For example, what would happen if you opened and closed a window in an application repeatedly? Or, what about performing two or three small actions in a variety of ways many times?
Would a real user actually do something thousands of times like this? Not unless they had some unusual compelling reason, such as entering data, closing the entry form, then re-opening and entering another item.
However, this small-scale test automation can reveal code defects, memory errors and other things that are sometimes seen in production use, but considered rare anomalies. One type of software testing that can benefit from this is video gaming, where actions are repeated many times in quick succession.
-
State-transition Testing
State-transition testing is another technique that has been around a long time, but can be highly effective in finding defects. This technique is based on the idea that an object, software or system can only be in one given state of being at a given time. The easiest example is an application is in “normal” state until some error is detected. Then, the application is in “error” state as shown in Figure 7. While in an error state, the user can’t do the same things as in the normal state. In fact, it may be that the user can only do one thing, which is to correct the error, before proceeding.
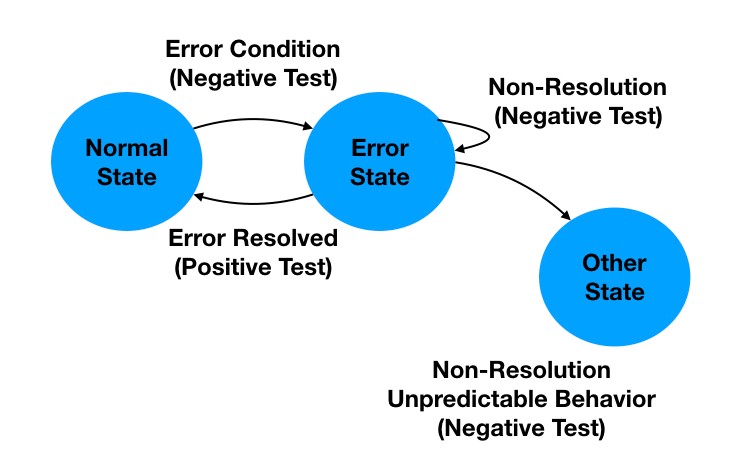
Figure 7 – State-Transition TestsA negative test in this situation would be to see if the error state is triggered by an invalid entry. Another negative test would see if it is possible to move to the normal state or some other state without resolving the error state. For example, would another invalid entry resolve the error state, or trigger another state?
The positive test would be to see if the error can be resolved with an expected action or entry.
Ideally, a state-transition diagram or model is the basis for this kind of test.
Balance is Needed!
It’s a good practice to have both positive and negative tests in your test set. I have seen situations where many negative tests were performed which yielded many defects. Yet, not enough attention was given to the positive tests to make sure the software worked upon release.
Conclusion
Negative testing is the most rigorous form of testing because it seeks to find where the software doesn’t work as opposed to simply trying to prove it works in given conditions. Positive tests are also needed, but they are a weaker form of testing because they don’t challenge the software or the requirements.
The techniques listed above have been described in many books on the topic. Two books I highly recommend on learning more about negative testing are:
The Art of Software Testing by Glenford Myers. Although there are three editions, I prefer the first edition.
A Practitioner’s Guide to Software Test Design by Lee Copeland. Lee does a great job in this book in presenting detailed examples in applying classic and new test design techniques for negative testing.
While balance is needed in test cases, negative tests should comprise a significant part of your testing library. Doing so will result in higher test effectiveness and the joy in finding those elusive bugs!
What is Negative Testing and why is it so important? In this article we explore the subject of testing to “break” a software and required techniques.
By Randall W. Rice
Published on:
Randall W. Rice, CTAL
Randall W. Rice is a leading author, speaker, consultant and practitioner in the field of software testing and software quality, with over 40 years of experience in building and testing software projects in a variety of domains, including defense, medical, financial and insurance.
You can read more at his website.