Regression testing can be a very difficult and time-consuming type of testing, even in the best of situations. In this article, we will consider nine proven practices that can make regression testing more effective and more efficient.
Introduction
Of all the types and forms of software testing, regression testing is perhaps the most misunderstood and misapplied type of testing. In this article, I will lay some foundational principles of regression testing, then show nine ways to make your regression more effective and efficient by making it more accurate and reliable.

What is Regression Testing?
First, let’s define the goal of regression testing. That is, regression testing is a way to detect if previously working functions in software no longer work correctly. In essence, we are seeking to learn if the software or system has regressed to a lower level of quality than before a change was made.
Regression testing is not testing a modification to the software to verify or validate the change. That is called “confirmation testing.” Regression testing is intended to ensure the correctness of functionality that did not change. You are trying to find any unintended consequences of a change.
Another point of confusion is to equate regression tests with build verification tests (BVT), smoke tests, and/or continuous integration (CI) tests. Build verification tests, closely related to CI tests are intended to verify the integrity of a build, not to verify or validate functionality to the level of a regression test. The goal is to know if a change has “broken the build.” A smoke test is a very basic test, or set of tests, intended to show that things work at a very initial level.
Table Of Contents
- The Scope of Regression Testing
- Principles of Regression Testing
- Coding Practices
- Nine Ways To Boost Your Regression Testing
- Summary
The Scope of Regression Testing
If we truly understood the potential impact of a change, regression testing would not be needed. But, since perfect impact analysis is not possible except in very trivial cases, we must leverage the unknown effects with other techniques, such as regression testing.
The question then becomes, “If possibly anything could be impacted by a change, how much regression testing should we perform?”
Conceivably, the scope of regression testing could be quite large, especially when you consider that changes in other system elements, such as operating systems and database management systems can impact the functionality of application systems. Also, non-software changes such as server upgrades can also impact overall system functionality and performance.
However, we must balance the amount of regression testing with risk, resources and tools.
In high-risk applications, such as safety-critical software, it is appropriate to test all cases as a regression test. In lower risk applications with low to moderate impact potential, regression tests may comprise a percentage of overall release testing.
Principles of Regression Testing
Once you understand the principles behind an activity, the practice of that activity makes more sense and is easier to apply. That especially holds true with regression testing. Consider these foundational principles for regression testing:
-
Each change made to a tested version of a software module, system or application invalidates previous tests.
This hits to the heart of why regression testing is needed. It’s important to understand that any form of testing is just a snapshot. What passed a test minutes ago may not pass the next time – even if no apparent changes were made. Testing only known changes may seem to be adequate, but in reality is quite inadequate. Consider the scenario in Figure 1.
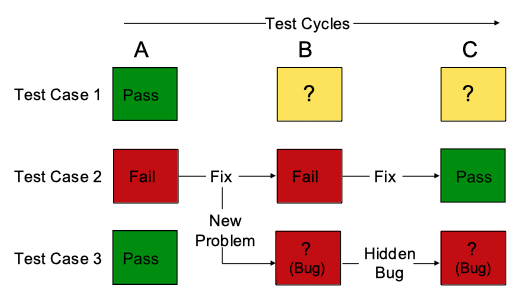
Figure 1 – The Risk of Hidden BugsIn this example, we have three test cases. The software is going through three cycles of change (or “builds”). We know that in the first test, cases #1 and #3 passed, but case #2 failed.
As a result of fixing the defect shown by case #2, a new defect was introduced. This defect will be found only if test case #3 is performed.
However, due to a tight deadline the decision is made to only test the changes to the software. This allows a “hidden defect” to be present in the final software release.
In this example, the test results are especially misleading because the second test case passed. Without regression testing, it would appear everything is OK. The only way to detect new defects and also to get the confidence that all planned tests pass before release is to test all regression test cases at each test cycle.
-
Build your regression suite over time.
While it might be tempting to want to build a large library of regression test cases at the outset of establishing regression testing, the time it would take to do so could increase the risk of letting important tests go unperformed.
It’s very common and wise for people to start small and simple and then grow their regression test suites.
Another good practice is to identify good regression tests as functional tests are being defined.
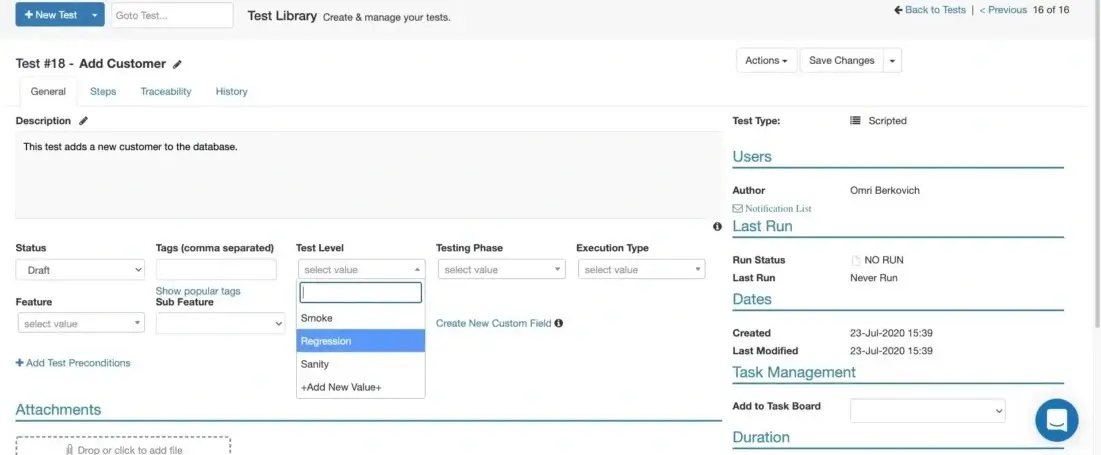
Test management tools such as PractiTest make this an easy task as shown in Figure 2. In this image, you can see the ability to classify tests as functional, regression and sanity. You can also add new classifications as needed.
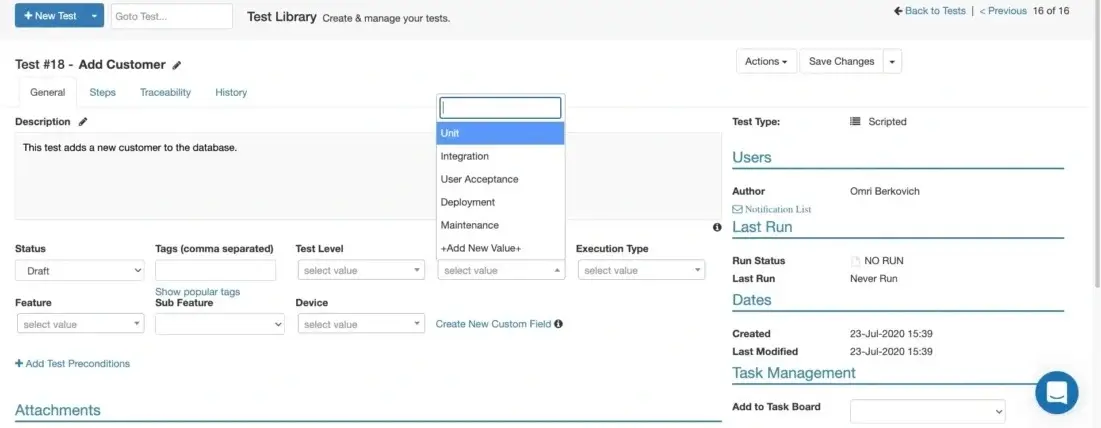
Another aspect of regression testing is that it can occur at any level or phase of testing: unit, integration, system, acceptance and maintenance (Figure 3). These levels can also be assigned in PractiTest and can also be customized to define other test levels.
-
Don’t forget maintenance!
As systems grow and change, so will the associated regression tests. That is why traceability between test cases and their basis (requirements, user stores, etc.) is so vital.
-
Complexity is the enemy.
High complexity in systems translates into high maintenance and very challenging tests to define and perform. In systems, complexity can arise from coding practices, environmental diversity, and degree of integration. Let’s look at each of these in a little more detail.


Coding Practices
One of the basic principles in software development and testing is that complex software code is more difficult to maintain and test. One way code complexity is measured is with the McCabe Cyclomatic Complexity metric, which is basically a count of the linearly independent paths in a component, module, procedure or even the entire codebase for an application. Just to give an idea of the testing challenge, a cyclomatic complexity metric over 10 is considered moderately difficult to test, and a score over 40 is considered high risk and untestable to achieve a complete level of coverage.
Environmental Diversity
The more components in the environment, the greater the scope of testing. In this context, a component can be hardware, software, and/or data. For example, if your target environment has four types of hardware platforms (PC, Mac, Android, iPhone), eight operating systems (Windows 10, Windows 8, MacOS X.15, MacOS X.14, Android X and Y, iPhone 13 and 12), four browsers (Chrome, Firefox, Safari, Edge), a main web site, an Android app, and an iPhone app, then you have three hundred and eighty-four possible environments, each of which to test all of your regression cases! If you have one thousand regression tests, then you would have to perform and evaluate three hundred and eighty-four thousand (384,000) tests each cycle of testing to get complete coverage of the environments with the regression tests defined.
Degree of Integration
High levels of integration between software modules and other system components makes regression testing a great challenge. The effect is seen when a change is made to one component (such as a software object), but the undesired effect (such as a system crash) is seen in a related system that is far-removed functionally from the modified object.
Nine Ways To Boost Your Regression Testing
-
Automate, Automate, Automate!
Did I say “automate” enough? The thing about regression testing is that even a very detailed difference from a previous correct test may indicate a defect. Since some of these differences are so small, it is virtually impossible to catch them all by manual tests. Plus, to perform a regression repeatedly at any significant scale requires exact precision. Manual regression testing has too much possibility for error. It’s very easy to accidentally press the wrong key or get a step out of sequence. This is why I call manual regression testing “pseudo-regression testing.” It may be close, but not exact.
One other reason for automation of regression testing is scope. Without test automation, it doesn’t take long to get tired and bored in testing. This leads to missing differences between versions of a test. In addition, think about trying to manually conduct thousands of tests and compare the results – perhaps thousands of pages of output. Clearly, tools are the only way to sustain this kind of effort.
-
Focus on Essential Functionality
Regression tests are often very simple and confirmatory. Sometimes, the tests are so simple, they appear trivial. However, these trivial functions may be the essential functionality needed to make the application usable.
As an example, consider a word processing application. While some functions, such as spell checking, merging documents and so forth, may be somewhat complex, they are not the most important functions in using the application. Instead, functions such as opening a document, creating a new document, saving a document, and printing a document are essential. If these functions don’t work correctly, the other more complex functions can’t even be performed.
Don’t underestimate the power of simple and essential functionality in regression testing!
-
Build a Restorable Test Data Source
The ability to conduct repeatable regression testing depends on having test data that can be managed in a repeatable way. Test data creation and management is something that is often not included with most test automation solutions, but must be included in some way.
In Figure 4, we see the basic process for regression testing, which includes repeatable and restorable test data.
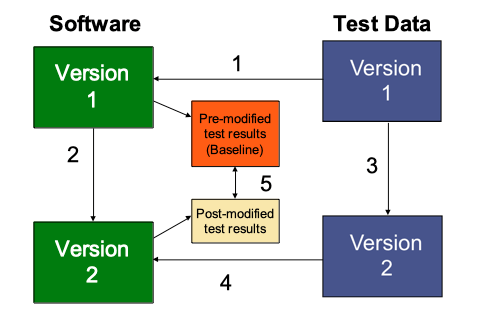
Figure 4 – The Basic Regression Testing ProcessIn the above process, the following steps are performed:
Step 1 - Test existing software using test data containing pre-modified test cases. The results of this test will be the baseline to compare against.
Step 2 – The software or system is modified.
Step 3 - Modify the test data to contain new test cases to validate changes.
Step 4 - Test modified software using modified test data.
Step 5 - Compare the post-modified test results with the pre-modified test results. Any differences should be identified as potential defects. The post-modified test results become the baseline for the next regression test, if they are shown to be correct.
Test automation tools often handle the testing of functionality and the comparison of results, but often fail at performing the test data maintenance shown on the right side of Figure 2. These functions are typically performed either manually or with a test data management tool.
Simple test data can often be created manually, although spreadsheets are notoriously unreliable. However, when test data becomes complex (such as the need to maintain relationship and integrity between data tables or databases) a test data management tool is needed to handle things such as data aging and data masking (or de-identification).
-
Control the Scope of Regression testing
At first, the scope of regression testing can be daunting. After all, so many functions and so little time to create, perform and evaluate the tests. Even with test automation, the time needed to create and maintain test automation is significant in most cases.
One of the best things you can do is to define the best easy targets for regression testing early on. Then, you can grow.
Even if you can only start with 50 or fewer regression tests, you can grow once you get the process down. Plus, the smaller initial size allows you to adjust the process early without losing large amounts of initial investment. I would rather learn from 50 regression tests early than 1,000 regression tests early on. Of course, these are arbitrary numbers just used for illustration. You would need to adjust your own scope based on your own capabilities, time, tools, risk and resources.
-
Design Efficient Tests
Just having a certain number of tests can be misleading. The real concern is how efficient are the tests?
For example, if one test could be designed to efficiently perform the same coverage of testing as four tests, you have achieved a 75% savings in test volume and test effort.
Some people get fooled by the idea that since tests are automated, it doesn’t matter how many tests are involved. However, it still takes a certain amount of time for all those automated tests to run. Plus, you have to investigate failures and maintain the tests. So, fewer tests that are meaningful are often more efficient than a large volume of tests that may be redundant.
To achieve test case efficiency, you will need to apply intermediate to advanced test design techniques which are purposed to get the most test coverage from the least number of tests. Examples include equivalence partitioning, decision tables and combinatorial techniques such as pairwise test design.
Test design tools are available, especially for combinatorial test design. Once generated, the test cases can then be imported into most test execution automation tools.
It is important to note that even with the test design tools to help create efficient test cases for regression testing, you will still have to manually define the expected results in many test generation tools.
While efficient tests are important, you will probably want to first identify the critical and essential functions mentioned earlier.
-
Have a Repeatable Processes
Regression testing is highly dependent on exact repeatability. This level of repeatability is difficult, if not impossible, to achieve without a larger highly repeatable testing process.
When conducting and comparing two regression tests of the same function, those tests need to be conducted as close to the same as possible. There may be variation due to changes in a new version, but the idea is to stay as consistent as possible.
-
Base Your Testing on Risk and Criticality
As with all of testing, you need to prioritize on the functions that carry the highest risk as defined by the likelihood of failure and associated impact of failure.
Criticality is related to risk, but different. Risk is a potential event with an estimated impact. Criticality is the degree of dependence upon a particular function, process or system.
Going back to the word processing example, opening a document is critical to the correct functioning and usability of the application. Based on likelihood of failure, opening a document may be a low to moderate risk. However, the open document function does have a high impact regarding the usefulness of the application.
The important distinction is that a critical function may not always be high risk. And, the opposite may be true. A high risk function may not be critical. For example, mail merge may be prone to problems, but would likely not prevent the application from being usable overall. -
Start when the application is stable enough to automate
This implies that the software must have predictable behavior that is not under constant high degree of change. If you try to start regression testing too early, you might find it takes more effort to maintain tests than is practical. This is not to say that early test automation isn’t helpful. However, starting regression testing too early may generate many differences since development is still underway.
Much of the decision of when to start building regression tests depends on the degree of fluidity during development. For example, if the user needs are constantly changing, it may be very difficult and time-consuming to maintain regression tests. But, there can still be regression defects even in highly dynamic software development. The key is to get understanding of the stability of a function (or set of functions) to the best degree possible in order to know when to start defining and performing regression tests.
-
At the system integration level, focus on scenarios instead of functions
A very common way of performing risk-based regression testing is to start with the high-risk and highly critical functions, then work down to the functionality with lesser risk and criticality.
This is fine until you need to test multiple functions that span risk and criticality levels. One problem is that in order to test a high-risk function, you must first test a low to moderate function.
Another problem with low-level risk assignment is that in highly integrated systems (which is rich territory for regression defects), it is easy to miss regression defects due to integration defects if the focus is on individual functions only.
The solution to this situation is to evaluate the scenarios to be tested and assess the risk and/or criticality of the scenario. Assessing risk and/or criticality at the scenario level allows you to focus on the larger functional tasks as opposed to smaller functions. This view is especially helpful when performing regression testing as part of system testing or user acceptance testing.
Summary
Regression testing is one of the most misunderstood and mis-applied forms of software testing. When designed and conducted without understanding the true purposes and benefits, regression testing can be a frustrating, time-consuming and low-value test activity.
Like all testing, complete exhaustive regression testing is impossible except for very trivial applications. However, using a wise combination of process, tools and human analysis, it is possible to gain great value and understanding by performing regression testing.
Hopefully, the tips in this article will help form a framework for your own effective regression testing of just about any type of application.
By Randall W. Rice
Published on:
Randall W. Rice, CTAL
Randall W. Rice is a leading author, speaker, consultant and practitioner in the field of software testing and software quality, with over 40 years of experience in building and testing software projects in a variety of domains, including defense, medical, financial and insurance.
You can read more at his website.